Navigating RAG: Selecting the optimal architecture for your needs
Magnus Lindberg ChristensenAlumn
Published 08 Nov 2024
Reading time 10 min
2023 and 2024 have witnessed high advancements with LLMs, especially with the emergence of numerous models varying in both size and capabilities. The proliferation of LLM providers is also present, offering various solutions for both hosting models and data across different storage systems, let it be on-premises or cloud-based. Because of the ample opportunities it has become more important for Developers and Solution Architects to thoughtfully consider the overall architecture of Retrieval-Augmented Generation (RAG) systems during application development.
Deciding on the right architecture isn’t a trivial task. The most suitable solution design must find a balance between performance, security, scalability, as well as cost-efficiency, while still aligning project requirements such as latency, customer expectations, and so forth.
In the following blog post, we will explore various architectural approaches for RAG systems ranging from entirely cloud-based solutions to fully local, on-premises solutions.
Overview of RAG architectural approaches
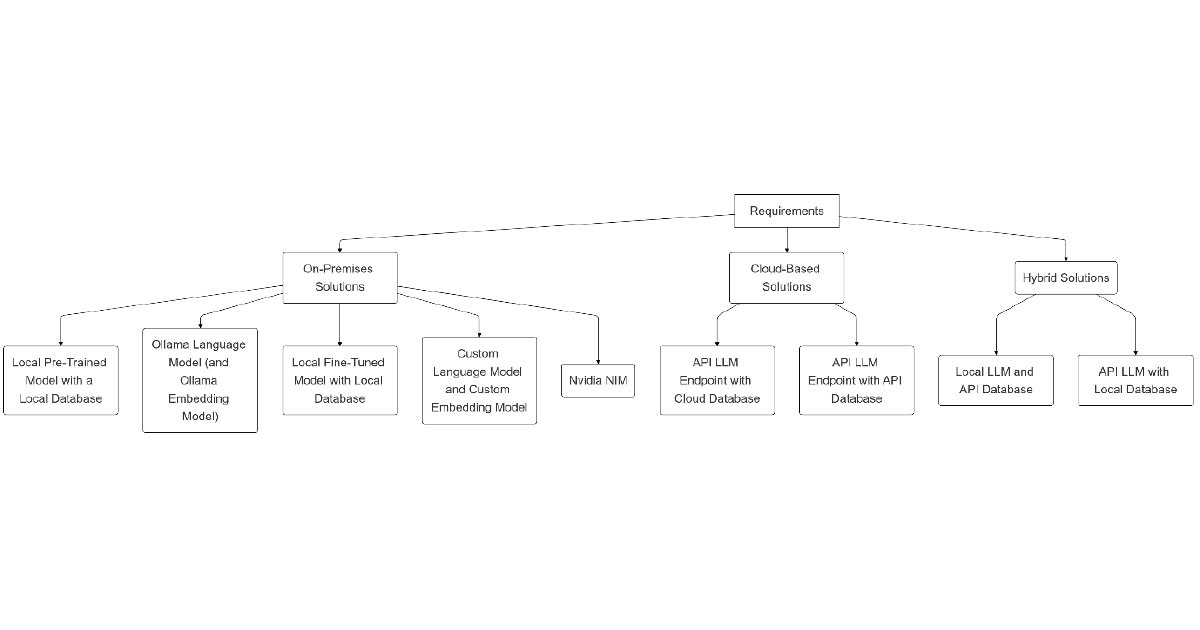
To start, it’s important to understand that the choice of architecture involves multiple decisions. The considerations are summarised below.
In this overview, we will categorise RAG architectures into three primary types: On-premises solutions, cloud-based solutions, and hybrid solutions. Each of the categories represents a certain approach to balancing the trade-offs of control, scalability, and resource utilisation.
On-premises solutions
In the context of RAG applications, on-premises solutions refer to architectures where both the LLM and the data storage are hosted entirely on local infrastructures. Generally, this approach offers greater control over data and ensures the maximum security possible in infrastructure, thus not considering the security of data preprocessing. Unfortunately, it also imposes more burdens in terms of setup, maintenance, and scalability. The following introduces several on-premises architectures that can be employed.
The local pre-trained model with a local database
In this architecture, a pre-trained LLM (such as Llama, Mistral, GPT-3, etc.) is selected and deployed on the local infrastructure. Additionally, an appropriate embedding model is used to transform the data into numerical vectors, which are then stored in a locally hosted database, such as a vector database, Elasticsearch, or others, depending on the system’s requirements.
Flexibility: Low
Customisability: Limited to fine-tuning
Scalability: Low. Require hardware upgrades
Model Change flexibility: Low. Require update of on-premises infrastructure
Pros
Enhanced privacy and security: Data never leaves the local environment, thus ensuring higher security
Compliance with data regulations: On-premises solutions make it easier to comply with regulations such as GDPR, especially when dealing with sensitive data
Complete control: Full ownership over both the model and the data infrastructure
Lower long-term costs: If the system is long-lived and relatively stable, hosting everything locally can result in lower operations costs by avoiding cloud subscription fees
No reliance on Internet connectivity: Operations can continue even if there is no Internet access
Cons
High initial costs and maintenance: Setting up and maintaining local servers, databases, and the model infrastructure is resource-intensive, requiring skilled personnel and significant initial investment
Limited scalability: Scaling up typically involves costly hardware upgrades, making this less flexible than cloud-based solutions
Hardware obsolescence: Hardware and software may quickly become outdated, and upgrading infrastructure may be costly and potentially complex
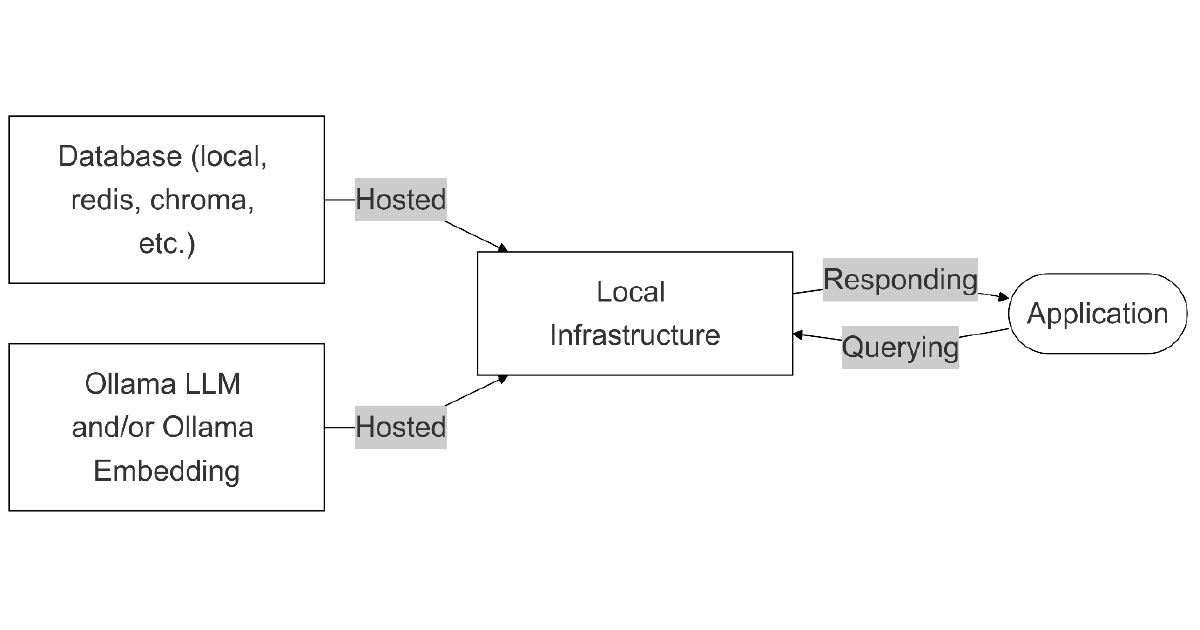
Ollama language (and embedding) model
Ollama is a third-party service that simplifies access to open-source language models while still maintaining local hosting. The architecture mirrors the previous example but relies on Ollama to streamline access to LLMs and embedding models (or any other third-party application with the same goal).
Flexibility: Medium. Access to several open-source models
Higher security with outsourced convenience: Sensitive data stays on-premises while benefiting from a more managed experience through Ollama
Customisability: Developers can choose from a variety of LLMs and embedding models tailored to their use
Flexibility: Ollama’s interface lets you quickly pull and deploy an LLM, providing more flexibility to change
Cost efficiency over time: Once set up, there are no recurring costs beyond infrastructure maintenance
Reduced development time: Ollama simplifies the management of language models, and thus the application development time may be reduced
Streamlined updates and integration: Ollama simplifies the integration with open-source models, thereby giving easier access to the latest models
Cons
Potentially increased latency: Depending on the integration specifies, latency may increase slightly, especially when combining components from multiple sources
Less scalability: Although Ollama simplifies model management, it does not eliminate the challenges of scaling on-premises systems
Third-party dependency: Even though data remains local, there remains a dependency on the Ollama platform, thus limiting complete autonomy
Limited customisability: Though the technique is flexible, complete customisation of model and infrastructure is still limited compared to fully do-it-yourself on-premises solutions
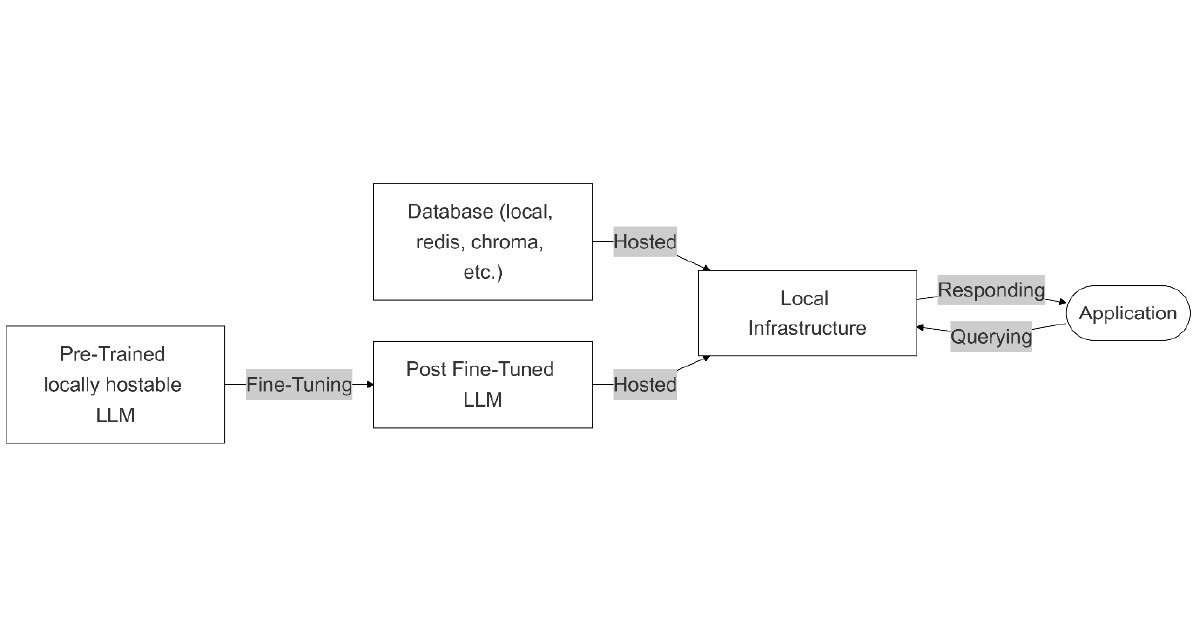
Local fine-tuned model with local database
A more specialised and domain-specific variation of the pre-trained model approach involves fine-tuning the model on domain-specific data. This allows for the creation of a tailored solution that is more suited to particular tasks and industries.
Flexibility: Low. Often set on a single model
Customisability: High. Fine-tuned model is highly customisable
Scalability: Limited. Require hardware updates and re-fine tuning if changes in models
Pros
Greater precision: Fine-tuning allows the model to specialise in the domain of the application, leading to more accurate and relevant results
Complete data control: Both the model and data stay on-premises, ensuring privacy and regulatory compliance
Customisation flexibility: Fine-tuning provides more control over the model’s behaviour and performance
Better long-term model optimisation: Fine-tuning allows for gradual optimisation as more specific data is introduced over time
Cons
Longer development time: Fine-tuning models is resource-intensive and requires specialised knowledge to ensure the model is optimally trained for the task
High maintenance overhead: Fine-tuned models require additional storage and computational power
Storage and resource demands: Fine-tuned models often require additional storage and computational power
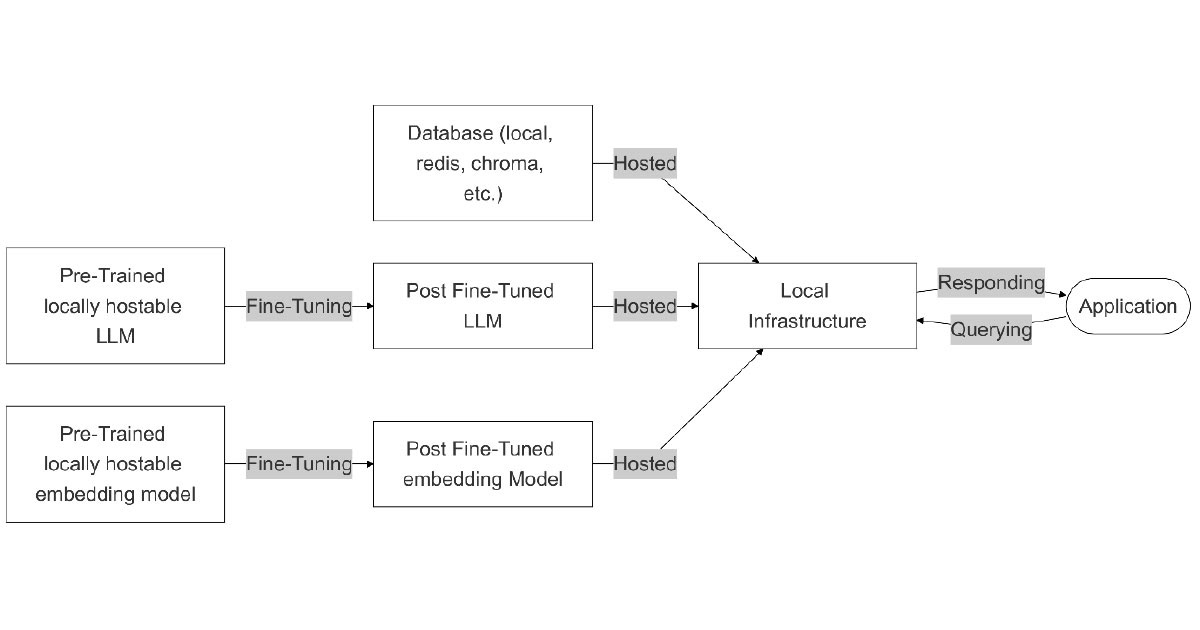
Custom language and embedding model
This approach goes beyond fine-tuning to also create a custom embedding model. This allows for full optimisation of both the language model and the embedding model to align with the specific domain of the application.
Flexibility: Low. Once build, this is what you use
Customisability: High. Both fine-tuned the LLM and the embedding model
Scalability: Low. Require hardware update and re-fine-tuning when changing the models
Pros
Complete domain-specific optimisation: Both the language model and the embedding model can be crafted to suit a particular domain, improving performance and accuracy
High security: As with other on-premises solutions, this approach ensures complete data privacy
Long-term cost efficiency: Once the system is in place, there are no ongoing subscription costs
Comprehensive data and model control: Control over every element of the pipeline allows for more robust optimization and security measures
Cons
High setup costs: The initial effort and cost to develop and fine-tune both models are significant
Resource intensive: Requires significant hardware, expertise, and time to develop and maintain
Less flexibility: Once a custom system is built, it can be more challenging to adapt or update it compared to off-the-shelf solutions
Require advanced expertise: Custom training both the LLM and embedding model requires deep expertise in machine learning, which could be a limiting factor for several teams
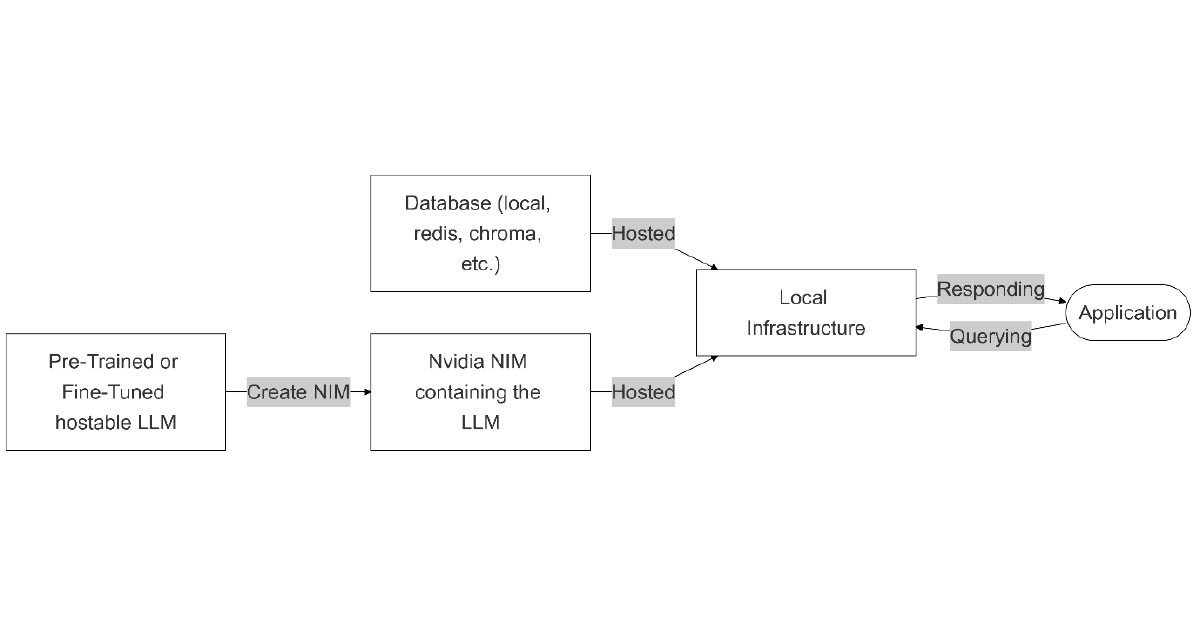
Nvidia NIM
Nvidia’s NIM is a specialised toolset optimised for LLMs and embeddings on Nvidia hardware. It is particularly suited for low-latency, high-performance applications in specific domains.
Flexibility: Medium. Require GPU accelerated systems (Nvidia in particular)
Customisability: Medium. You can fine-tune models but can’t do whatever you want
Scalability: Low. Scaling requires updated Nvidia Hardware investments, which may be costly
Pros
Optimised performance: Nvidia’s hardware and software ecosystem allows for extremely low-latency solutions
Fine-tuned precision: Models can be fine-tuned for specific domains, thus increasing their relevancy and accuracy
High security and privacy: As a locally hosted solution, all the data remains within the organisation
Specialised for GPU acceleration: Navidia’s hardware ecosystem is well-suited for accelerated machine learning tasks, providing significant performance boosts
Cons
Limited scalability: Scaling such a solution requires further investment in specialized Nvidia hardware
High initial costs: Setup and maintenance costs are substantial, particularly for organisations without existing Nvidia infrastructure
Less hardware flexibility: Dependency on Nvidia limits flexibility to switch hardware ecosystems, and their solutions might not be portable to non-Nvidia systems
Dependency on Nvidia ecosystem: The architecture is coupled to Nvidia hardware, which may reduce flexibility when adapting to other platforms
Cloud-based solutions
At core of cloud-based solutions their leverage external infrastructure, where models and data are hosted on cloud platforms and accessed via APIs. These architectures often offer greater scalability and flexibility but introduce concerns about privacy, security, and long-term costs.
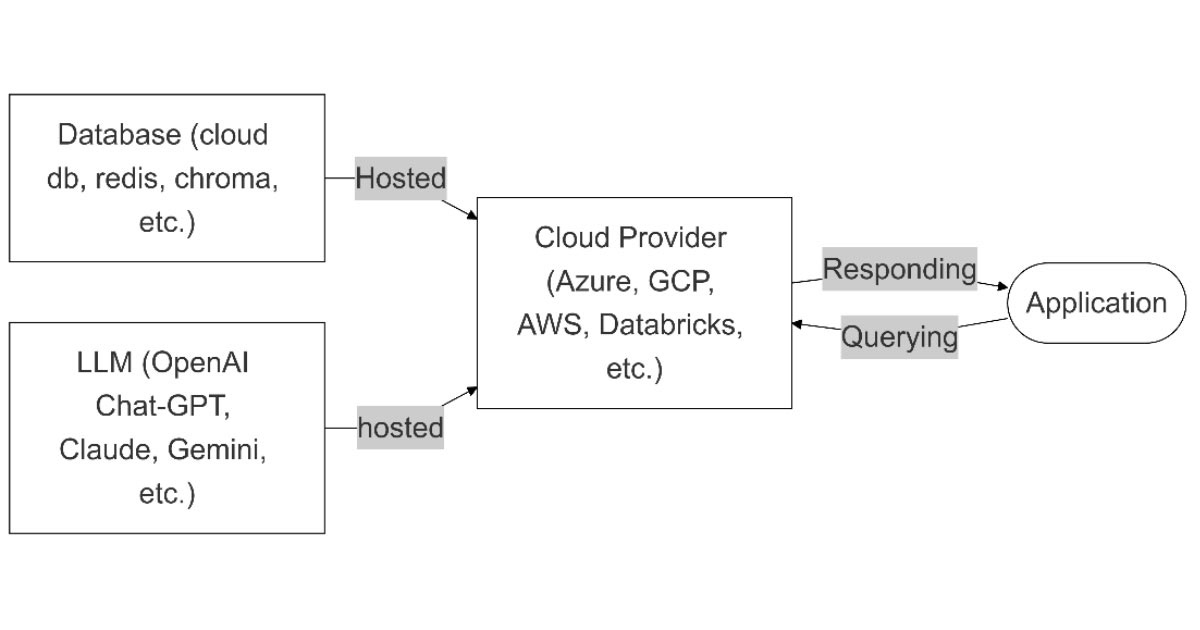
API LLM endpoint with cloud database
In this architecture, the language model is selected and hosted on a cloud platform, such as Azure or AWS. The data is stored in a cloud-based database, thus providing a seamless and scalable solution for RAG applications
Flexibility: High. It is reasonably easy to change models
Customisability: Low, as you are often restricted to the cloud provider
Scalability: High. It is easy to scale on the cloud by just increasing the subscription
Pros
Reduced initial cost: Cloud platforms eliminate the need for significant upfront investment in hardware
Scalability: Cloud infrastructure allows for rapid scaling to meet a particular demand
Convenience: The cloud provider manages maintenance and updates, reducing the need for internal resources
Rapid deployment: Cloud solutions can be deployed and scaled much faster than on-premises setups
Cons
Privacy and security concerns: Sensitive data is processed on external servers, raising issues on compliance with data privacy regulations
Ongoing costs: While initial costs are lower, ongoing subscription fees and pay-per-use charges can add up
Reliance on external providers: The system is fully dependent on the reliability and availability of the cloud provider
Provider lock-in: Moving away from a cloud provider can be costly and complex once reliant on their ecosystem
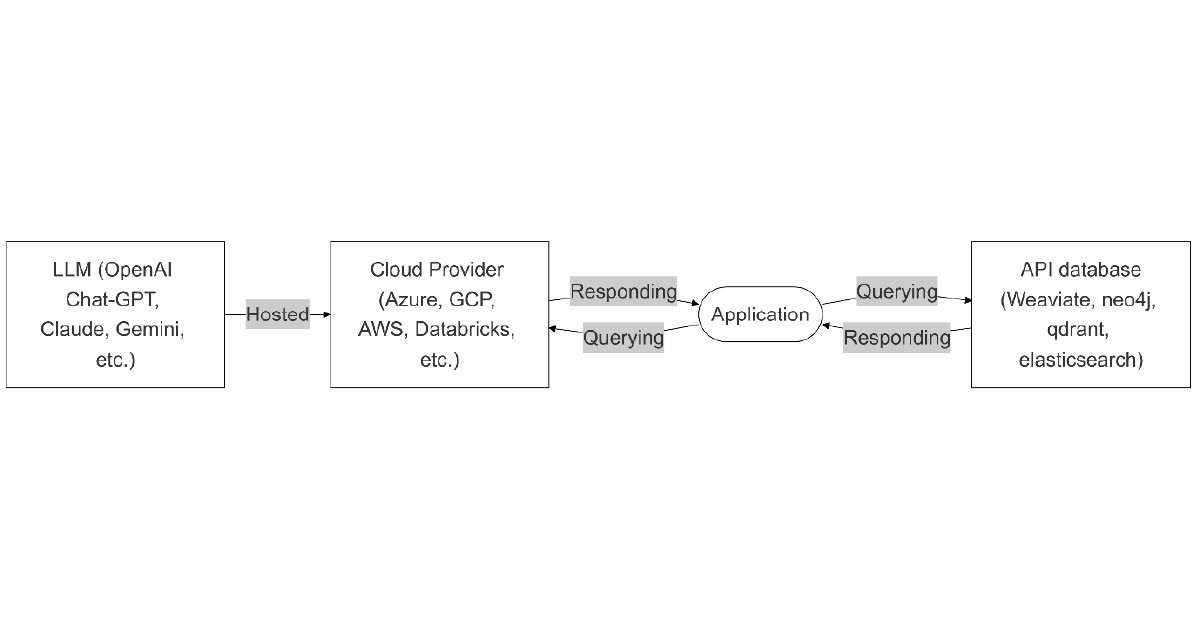
API LLM endpoint with API database
This architecture further decentralises the above solution by hosting the language model and database on separate cloud providers, accessed through respective APIs.
Flexibility: Very high. It is easy to change different components from different providers
Customisability: Medium. More setting configurations due to the several providers
Scalability: Very high. The model and database can be scaled independently
Pros
Flexibility: By selecting different providers for the model and database, developers can optimize each component for their specific needs
Scalability: Both the model and database can scale independently, allowing for more precise control of the resources
Cons
Increased complexity: Managing multiple APIs introduces additional complexity in synchronisation, which may lead to performance issues and potentially higher latency
Higher long-term costs: Utilising multiple cloud providers can lead to higher operational expenses, particularly when scaling across providers
Lower data control: Distributing data and processing across multiple providers can introduce more privacy risks
Increased data transfer latency: Data moving between providers introduces additional latency considerations
Data security complexity: Relying on multiple API providers requires complex security measures to ensure data integrity and privacy
Hybrid solutions
Hybrid architectures try to combine the benefits of both on-premises and cloud-based solutions, thus offering a compromise between control and scalability. These approaches are often favoured when organisations need to balance e.g. privacy with resource flexibility.
Local LLM and API database
In this architecture, a language model is hosted locally, while the database is accessed via an API from a chosen cloud provider. This approach balances local control over the model with the scalability of cloud-based storage.
Flexibility: High. Combines both on-premises and cloud capabilities
Customisability: Medium. Local control of the LLM but limited to the Database
Scalability: Medium. Difficult to scale the local model, but very easy to scale the database
Pros
Privacy for model processing: Keeping the LLM on-premises ensures that sensitive data remains under local control
Lower infrastructure costs: By outsourcing the database, organisations can reduce the costs associated with maintaining large-scale storage
Scalability for data: Cloud databases offer flexible storage solutions that can grow with the application’s need
Reduced on-premise storage burden: Offloading the database reduces the storage burden on local servers and makes the system more efficient
Cons
Latency and synchronisation Issues: The separation between the model and database can introduce latency, particularly when handling large volumes of data
Complexity in management: Maintaining synchronisation between local and cloud components adds to the overall system complexity
GDPR and data privacy: Careful considerations are required to ensure compliance with data
Increased cloud dependence for data: While the model is local, database access still relies on cloud availability and performance
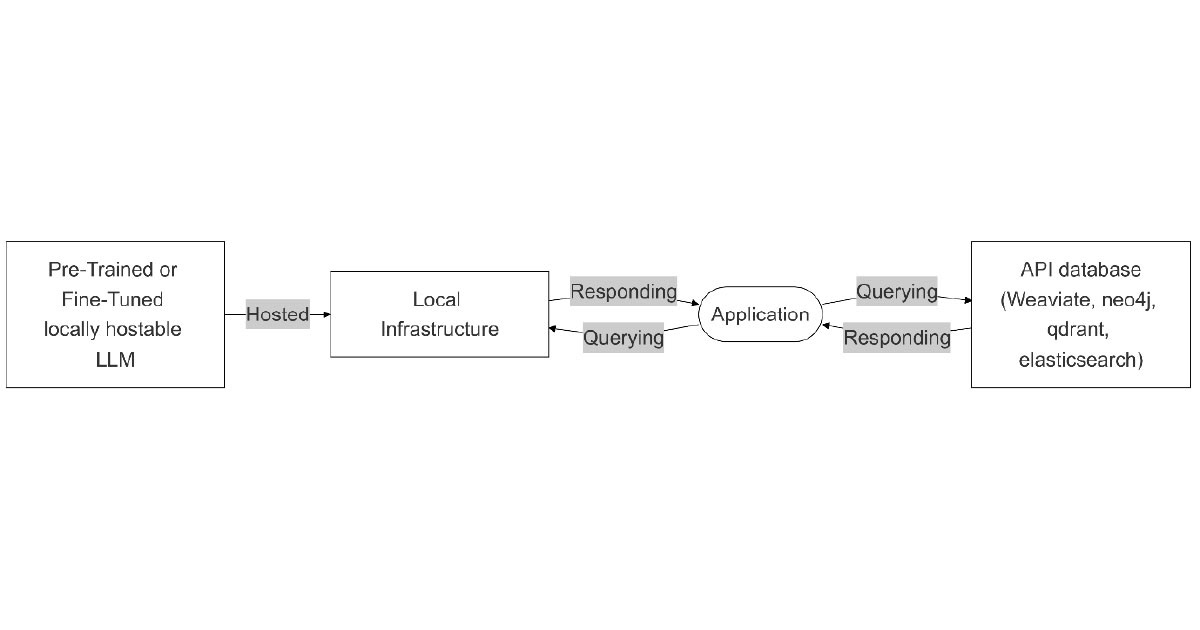
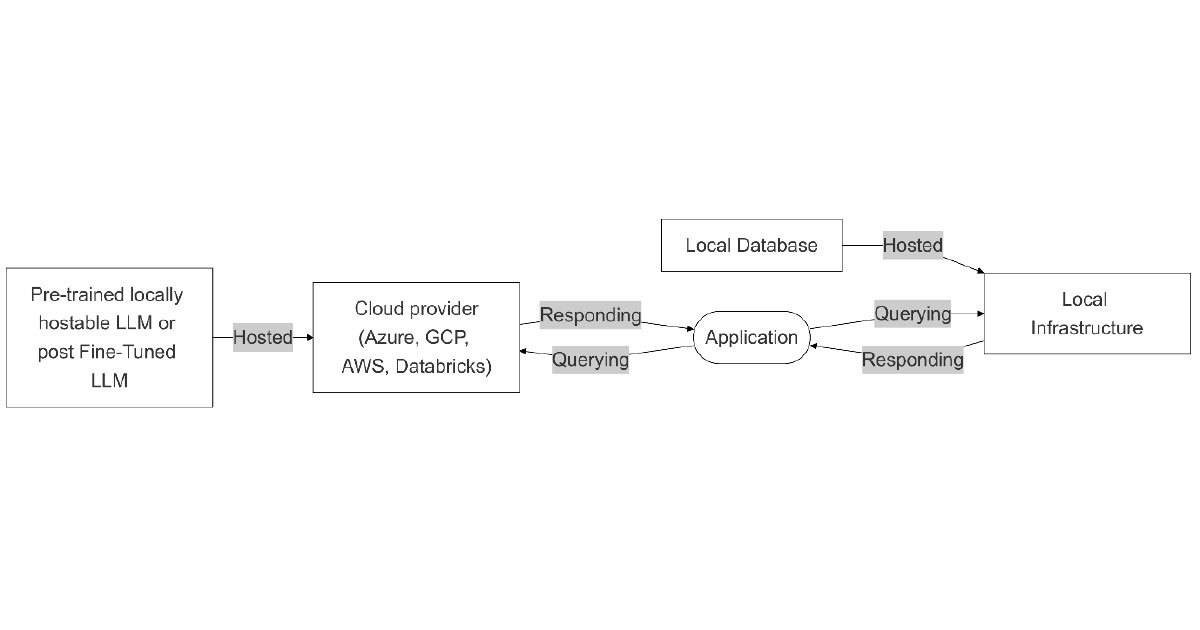
API LLM with local database
In this architecture, the language model is hosted in the cloud, while the data is stored locally. This setup is useful for organisations that prioritise control over their data but wish to leverage the scalability and flexibility of cloud-based LLMs.
Flexibility: High. Leverages cloud capabilities for LMMs but retains the sensitive data locally
Customisability: Low. LLMs on the cloud can’t be deeply customised Scalability: Medium. Great scalability for the model, yet limited for the local storage, as this requires further hardware investments
Pros
Data control: Sensitive data is stored locally, providing greater security and compliance with privacy regulations
Lower initial costs: By relying on cloud-hosted LLMs, organisations avoid the need for expensive local hardware to support large models
Scalability: The cloud-based model can scale to meet increasing demand without the need for costly hardware upgrades
Cons
Dependency on cloud provider: The system’s performance is reliant on the availability and reliability of the cloud provider
Latency issues: There may be increased latency when communicating between the cloud-hosted model and the local database
Ongoing cloud costs: Utilising cloud-based LLMs introduces recurring subscription fees, which can accumulate over time
Conclusions
Selecting the optimal architecture requires careful consideration of multiple factors, including latency requirements, data security, scalability, and resource availability. On-premises solutions provide unparalleled control and security but come with high upfront and ongoing costs for maintenance. Cloud-based solutions offer flexibility and scalability but introduce privacy concerns and may be costly in the long term. Hybrid architectures attempt to strike a balance between these, allowing for both scalability and control, though they may introduce more complexity and synchronisation challenges.
By evaluating the unique needs of the application, such as domain-specific requirements, the size and sensitivity of the data, and the available resources for development and maintenance, developers can make informed decisions that ensure a robust and efficient architecture tailored to their project’s goals.
Ultimately, there is no one-size-fits-all solution, but careful planning and consideration will lead to an architecture that best meets the needs of both the organisation and its users.