Three steps to be intentionally agnostic about tools. Reduce technical debt, increase stakeholder trust and make the objective clear. Build a machine learning system because it adds value, not because it is a hammer to problems.
As data enthusiasts, we love to talk, read and hear about machine learning. It certainly delivers value to some businesses. However, it is worth taking a step back. Do we treat machine learning as a hammer to problems? Maybe a simple heuristic does the job with substantially lower technical debt than a machine learning system.
Do machine learning like the great engineer you are, not like the great machine learning expert you aren’t.
Google developers. Rules of ML.
In this article, I look at a structured approach to choosing the next data science project that aligns with the business goals. It combines objective key results (OKR), value-feasibility and other suggestions to stay focused. It is especially useful for data science leads, business intelligence leads or data consultants.
Why data science projects require a structured approach
ML solves complex problems with data that has a predictive signal for the problem at hand. It does not create value by itself.
So, we love to talk about Machine learning (ML) and artificial intelligence (AI). On the one hand, decision-makers get excited and make it a goal: “We need to have AI & ML”. On the other hand, the same goes for data scientists who claim: “We need to use a state-of-the-art method”. Being excited about technology has its upsides, but it is worth taking a step back for two reasons.
- Choosing a complex solution without defining a goal creates more issues than it solves. Keep it simple, minimise technical debt. Make it easy for a future person to maintain it, because that person might be you.
- A method without a clear goal fails to create business value and erodes trust. Beyond the hype around machine learning, we do data science to create business value. Ignoring this lets executives reduce funding for the next data project.
This is nothing new. But, it does not hurt to be reminded of it. If I read about an exciting method, I want to learn and apply it right away. What is great for personal development, might not be great for the business. Instead, start with what before thinking about how.
In the next section, I give some practical advice on how to structure the journey towards your next data project. The approach helps me to focus on what is next up for the business to solve instead of what ML method is in the news.
How to choose the next data science project
Rule 1: Don’t be afraid to launch a product without machine learning.
Google developers. Rules of ML.
Imagine you draft the next data science cases at your company. What project to choose next? Here are three steps to structure the journey.
Photo by Leah Kelley from Pexels
Step 1: Write data science project cards
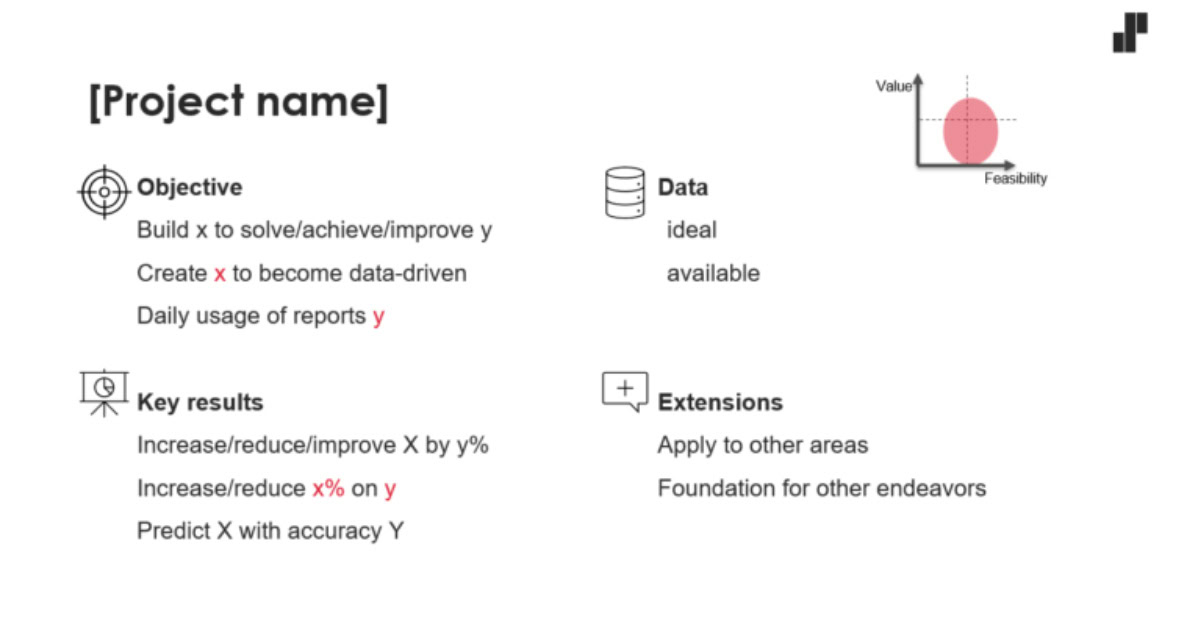
The data science project card helps to focus on business value and lets you be intentionally agnostic about methodologies in the early stage
Summarise each idea in a data science project card which includes some kind of OKR, data requirements, value-feasibility and possible extensions. It covers five parts which contain all you need to structure project ideas, namely an objective (what), its key results (how), ideal and available data (needs), the value-feasibility diagram (impact) and possible extension. What works for me is to imagine the end product/solution to a business need/problem before I put it into a project card.
Find the project card templates as markdown or powerpoint slides.
I summarise the data science project in five parts.
- An objective addresses a specific problem that links to a strategic goal/mission/vision, for example: “Enable data-driven marketing to get ahead of competitors”, “Automate fraud detection for affiliate programs to make marketing focusing on core tasks” or “Build automated monthly demand forecast to safeguard company expansion”.
- Key results list measurable outcomes that mark progress towards achieving the objective, for example: “80% of marketing team use a dashboard daily”, “Cover 75% of affiliate fraud compared to previous 3 month average” or “Cut ‘out-of-stock’ warnings by 50%, compared to previous year average”.
- Data describes properties of the ideal or available dataset, for example: “Transaction-level data of the last 2 years with details, such as timestamp, ip and user agent” or “Product-level sales including metadata, such as location, store details, receipt id or customer id”.
- Extensions explores follow-up projects, for example: “Apply demand forecast to other product categories” or “Take insights from basket analysis to inform procurement.”
- The value-feasibility diagram puts the project into a business perspective by visualising value, feasibility and uncertainties around it. The smaller the area, the more certain is the project’s value or feasibility.
To provide details, I describe a practical example how I use these parts for exploring data science projects. The journey starts by meeting the marketing team to hear about their work, needs and challenges. If a need can be addressed with data, they become the end-users and project target group. Already here, I try to sketch the outcome and ask the team about how valuable it is which estimates the value.
Next, I take the company’s strategic goals and formulate an objective that links to them following OKR principles. This aligns the project with mid-term business goals, makes it part of the strategy and increases buy-in from top-level managers. Then I get back to the marketing team to define key results that let us reach the objective.
A draft of an ideal dataset gets compared to what is available with data owners or the marketing team itself. That helps to get a sense for feasibility. If I am uncertain about value and feasibility, I increase the area in the diagram. It is less about being precise, but about being able to compare projects with each other.
Step 2: Sort projects along value and feasibility
Value-feasibility helps to prioritise projects, takes a business perspective and increases stakeholder buy-in.
Ranking each project along value and feasibility makes it easier to see which one to prioritise. The areas visualise uncertainties on value and feasibility. The larger they stretch along an axis, the less certain I am about either value or feasibility. If they are more dot-shaped, I am confident about a project’s value and its feasibility.
Note that some frameworks evaluate adaptation and desirability separately to value and feasibility. But you get low value when you score low on either adaptation or desirability. So, I estimate the value with business value, adaptation and desirability in my mind without explicitly mentioning it.
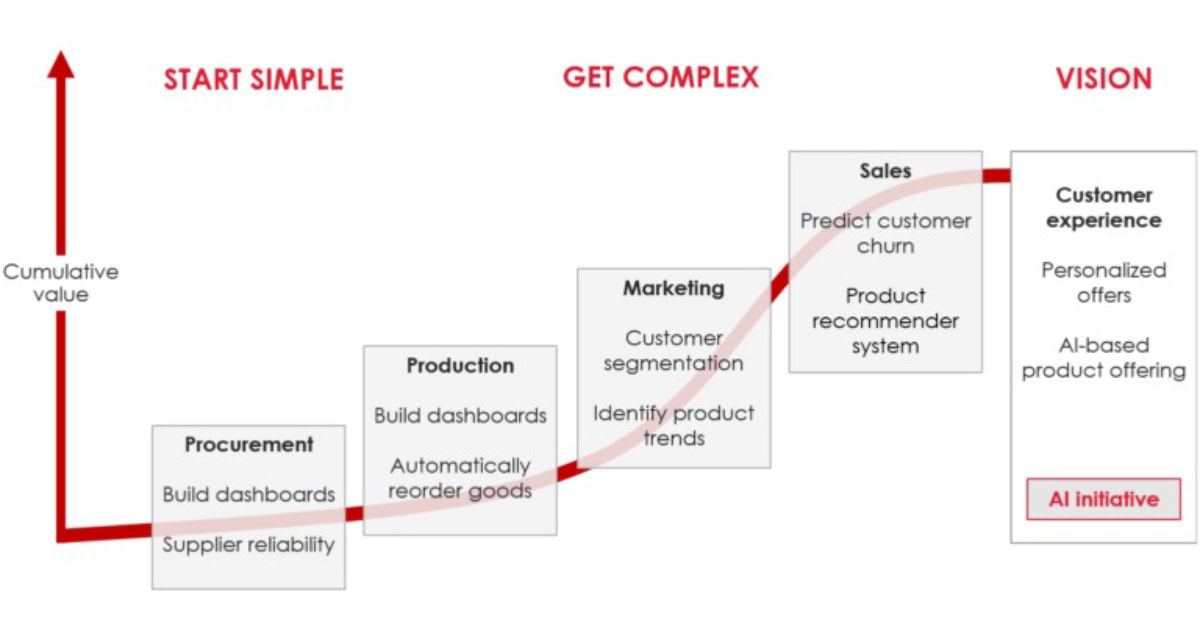
Data science projects tend to be long-term with low feasibility today and uncertain, but potentially high future value. Breaking down visionary, less feasible projects into parts that add value in themselves could produce a data science roadmap. For example, project C which has uncertain value and not feasible as of today, requires project B to be completed. Still, the valuable and feasible project A should be prioritized now. Thereafter, aim for B on your way to C. Overall, this overview helps to link projects and build a mid-term data science roadmap.
Here is an example of a roadmap that starts with descriptive data science cases and progresses towards more advanced analytics such as forecasting. That gives prioritisation and helps to draft a budget.
Step 3: Iterate around the objective, method, data and value-feasibility
Be intentionally agnostic about the method first, then opt for the simplest one, check the data and implement. Fail fast, log rigorously and aim for the key results.
Implementing data science projects has so many degrees of freedom that it is beyond the scope of this article to provide an exhaustive review. Nevertheless, I collected some statements that can help through the project.
- Don’t be afraid to launch a product without machine learning. And do machine learning like the great engineer you are, not like the great machine learning expert you aren’t. (Google developers. Rules of ML.)
- Focus on fa ew customers with general properties instead of specific use cases (Zhenzhong Xu, 2022. The four innovation phases of Netflix’s trillions scale real-time data infrastructure.)
- Keep the first model simple and get the infrastructure right. Any heuristic or model that gives quick feedback suits at early project stages. For example, start with linear regression or a heuristic that predicts the majority class for imbalanced datasets. Build and test the infrastructure around those components and replace them when the surrounding pipelines work (Google developers. Rules of ML. Mark Tenenholtz, 2022. 6 steps to train a model.)
- Hold the model fixed and iteratively improve the data. Embrace a data-centric view where data consistency is paramount. This means, reduce the noise in your labels and features such that an existing predictive signal gets carved out for any model (Andrew Ng, 2021. MLOps: From model-centric to data-centric AI).
- Each added component also adds a potential for failure. Therefore, expect failures and log any moving part in your system.
- Test your evaluation metric and ensure you understand what “good” looks like (Raschka, 2020. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning.)
There are many more best practices to follow and they might work differently for each of us. I am curious to hear yours!
Conclusion
In this article, I outlined a structured approach for data science projects. It helps me to channel efforts into projects that fit business goals and choose appropriate methods. Applying complex methods like machine learning independent of business goals risks accruing technical debt and at worst jeopardises investments.
I propose three steps to take action:
- Write a project card that summarises the objective of a data science case and employs goal-setting tools like OKR to engage business-oriented stakeholders.
- Sort projects along the value and feasibility to reasonably prioritise.
16. Iterate around the objective, method, data and value-feasibility and follow some guiding industry principles that emerged over the last years.
The goal is to translate data science use cases into something more tangible, bridging the gap between business and tech. I hope that these techniques empower you for your next journey in data science.
Happy to hear your thoughts!