What is data-oriented design?
As stated above, data-oriented design (DOD) is a programming paradigm like object-oriented programming (OOP), functional programming (FP) or procedural programming.
It is often easier to explain DOD by contrasting it to other paradigms.
To use OOP as an example, OOP concerns itself with objects (which are instantiations of classes), which contain fields or “attributes”, which is our data, and procedures called “methods”, which is our code.
The OOP paradigm invites the programmer to model the problem domain directly in the code, such as making a “car” object, with “wheels”, “colour” and “brand” attributes, and a “drive” method.
This is a convenient way to design the system, as it is rather intuitive. Unfortunately, the resulting system is often not what the problem domain actually looks like, or rather, a solution for a given problem domain is not a 1-to-1 translation of the real world into code.
The high level of abstraction in OOP also creates a clear separation from the underlying computer hardware. The abstract objects can vary greatly in structure making it harder to search for them and store them under the same conditions in memory. An OOP system would ask the hardware to treat a “dog” object and a “car” object similarly in memory.
DOD eliminates a lot of the hardware abstractions. It accepts that the role of a system is to take input data, transform it on given hardware, and give output data.
Data, in this sense, could just be an array of numbers, such as [3, 4, 5], which doesn’t mean much on its own, but if it was put in the context of coordinates in the x, y and z axis, it suddenly gains meaning. So, the DOD programmer accepts that data can be similar, such as the number of legs on a dog, for instance, 4, or the number of wheels on a car, for instance, 4, again. It is only in the context of dog legs or car wheels that the number 4 has a specific meaning.
This approach is particularly helpful for real-time graphical applications, such as in video games, since the position of one object isn’t fundamentally different from the position of another object. Likewise, the two positions will have the same data transformations applied to them, such as translating them. With this knowledge, positions can be stored together, creating packed memory which the hardware prefers, and performing the same transformation to all of it, something that the computer also likes.
Thus, we begin to see that data isn’t the problem domain, as it is fundamentally meaningless. In the same vein, the problem domain is also not the code. The “dog” as such, doesn’t exist as an object. In this way, the programmer gives up some of the human-friendly readability, but in return, they also gain freedom from the constraints abstractions like this would bring, and its effects on the underlying hardware. To DOD there is no difference between a car driving or a dog moving if all it’s doing is changing its position. In this regard, we’re also closer to the much sought-after code reuse, as there are very few algorithms that cannot be reused on primitive types.
We have also come to another truth for the DOD programmer, which is that our data, without meaning, has no structure. There is no “dog” structure. The dog is rather implicit from a combination of data within the system. And in many regards, it is easier for the DOD programmer to have evolving systems, since they don’t have to update a dog object, and all the objects dependent on the dog object, such as a kennel or dog owner. Rather, they just add more data to the system and more transformations.
In fact, it could be said, DOD doesn’t require a final design of the system as it isn’t context-dependent, rather it only concerns itself with the data and transformations needed to meet use cases. On the other hand, this lack of strict structure and expectation that the programmer understands the intricacies of the underlying hardware requires more discipline of the programmer since the programming paradigm doesn’t hold his/her hands.
Why use data-oriented design?
Less complexity
To quantify the complexity of a given system we often use cyclomatic complexity. This is a metric that concerns itself with the branching of flow control. We start at one and increase the value by one for each if statement, while statement and each case of a switch statement.
Virtual calls, such as when using inheritance, for instance, an interface, essentially work like a switch statement by looking into a call table and picking the correct function pointer. We therefore also count each override.
However, this is typically not what causes the most complexity for a system – that is caused by “state”. Consider a light switch. It can be turned on or off. It has two states. Now consider two light switches. Each permutation is a state; off/off, on/off, off/on and on/on. If we then wanted to track whether the room was “very bright” (on/on), one might be tempted to have this as a boolean.
With this in mind, it is important to eliminate unnecessary flow control branching, such as those that only exist due to using a specific programming paradigm, and not to solve the use-case.
Likewise, we should avoid introducing an extra state to our system, that could instead be implicitly determined. For instance, if we characterise having both light switches on, as being “very bright”. We can introduce a boolean that reflects if it is very bright, but this is an extra state, that isn’t strictly needed. Instead, we should interrogate the state of our current system to see if “very bright” is met – whether both light switches are set to “on”.
Better performance
Something important to note about flow control branching and state is its statistical nature. What is the most common use case? Not necessarily the domain use case, but the actual use case in the system under use. By considering which parts of our system are the most common, we can program for these cases, and help the branch predictor. If we take our light switch from earlier and assume it has a random chance of being either on or off, we will get a branch prediction success rate of 50 %. This means that 50 % of the time, the CPU guesses wrong and must retrieve different instructions into the cache, losing up to 10 to 20 cycles each time. While 10 to 20 cycles don’t seem like a big deal, remember this is simply for a two-state system with a single branch. If we’re working with real-time datasets of considerable size, this will quickly add up. Even if performance isn’t an explicit feature of a project, it still makes sense to improve it by embracing a methodology that defaults to making optimal performance choices.
A way to solve our light switch use case would be to have two different lists. One containing all light switches that are on and one containing all light switches that are off. If we need to perform a given transform only on light switches that are on, we simply give it the list of light switches that are on. Compared to having a single list with all light switches, we now have no need to check their state within our procedure, thus avoiding branching and potential branch prediction misses, since we now know that all light switches we operate on are turned on.
In this example, turning a light switch off would simply be deleting it from the “on”-list and inserting it into the “off”-list.
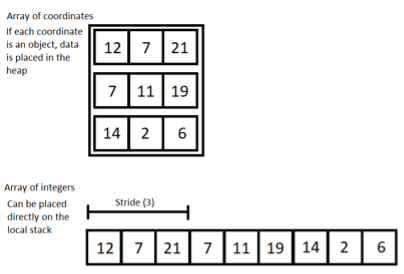
We also help the computer by only working with primitive types. We work with “structs of arrays” rather than “arrays of structs”. An example could be an array of positions in 3D space. The positions might be a vector object, or it might be a 3-dimensional array. However, the interpretation that the numbers in this array are actually positions, doesn’t have to be part of the system. Instead, we can simply store every number in a single one-dimensional array of integers, placing the 3 coordinates for a given position sequentially after each other. Now, to get the 3 coordinates for a particular position, we take the positions index multiplied by the stride, which in this case would be three. The 3 numbers at the resulting index and the next two elements are then the coordinates for the position (see Figure 1).